前言
先上链接:
表情包大全智能体(热度6w+):https://chatglm.cn/main/gdetail/6615735eaa7af4f70cf3a872
视觉标注数据开源Repo:https://github.com/LLM-Red-Team/emo-visual-data
智谱GLM直播回放:https://www.bilibili.com/video/BV1qm411y7EP
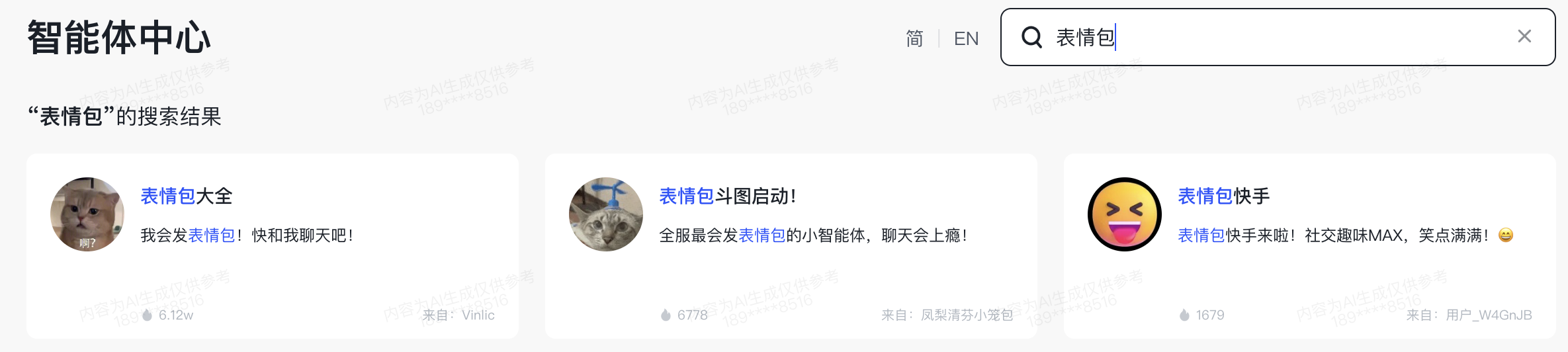
在智谱清言的智能体中心,搜索表情包,热度最高的三个智能体都是使用下文介绍的方式实现。
起源
国内大模型应用平台在今年迎来爆发性增长,智能体(Agent)作为LLM大模型能力的核心应用形式也被重视起来,智谱清言是国内最早上线完整智能体中心的平台,跟随着一起上线的是更强悍的GLM4模型作为Agent驱动底座。
这意味着真正的人人都是产品经理的时代开始了,每个人都可以通过描述需求来设计一款AI应用,同时也都在思考怎么才能制作爆款智能体。
我自己在想现在LLM的响应总是充满机感(不够拟人),期间也试过把微信群聊记录提取出来,输入到知识库作为检索增强,但是只有在话题与记录相关度比较高时才能复刻一些比较有趣的对话,如果要实现更真实的对话就必须要进行模型微调训练,这个代价就更大了。
那有什么让LLM更拟人的方案?
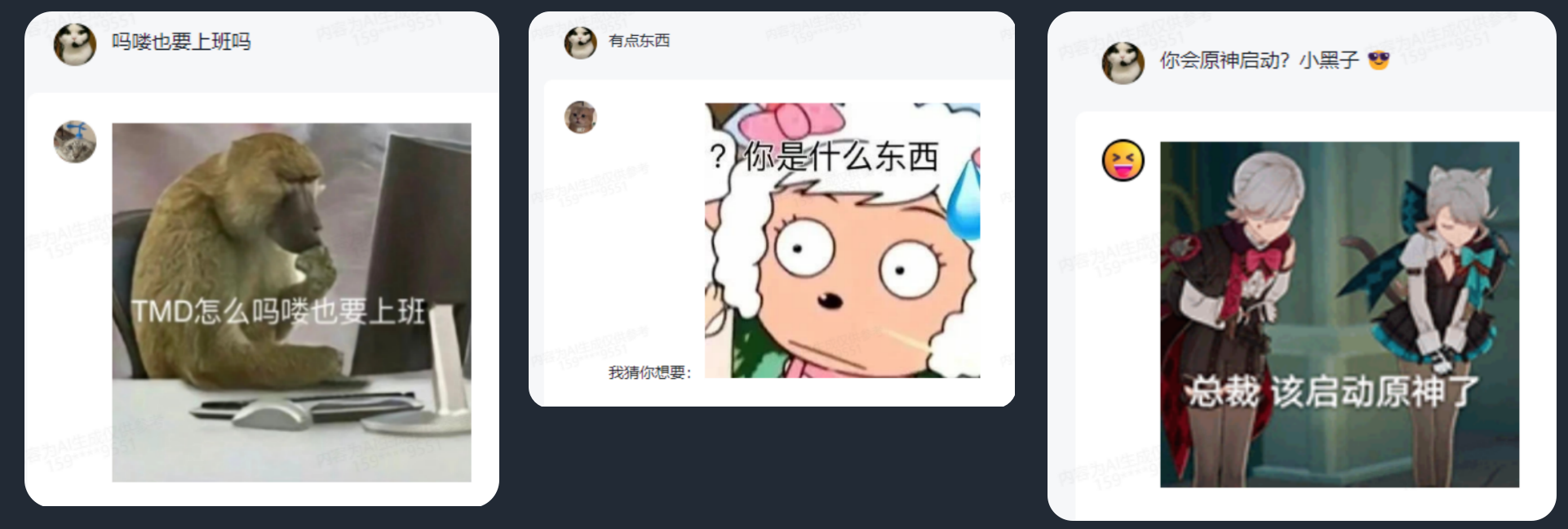
哎!我发现原来缺了点表情包!假如模型会发表情包岂不是很好玩?
表情包是一种模因,模因就是可以被人模仿并传递给其他人的信息,比如一段音乐、一个观念、一个时尚趋势、一句流行语、一个动作等等,但不是所有模因都像表情包这样能够简洁表达一种心境,还具有高度的传染性和多样性,每次发送和接收表情包都会让我们大脑产生多巴胺。
借助多模态大模型的视觉推理对表情包图像进行数据标注,再将这批数据作为知识库内容,智谱清言是否有能力通过用户输入的query来RAG(检索增强)检索到语义最接近的表情包数据,然后将相应的表情包图像文件名输出?
由于平台内部RAG实现并不透明,但我们可以先简化并猜测一下智能体的执行流程:
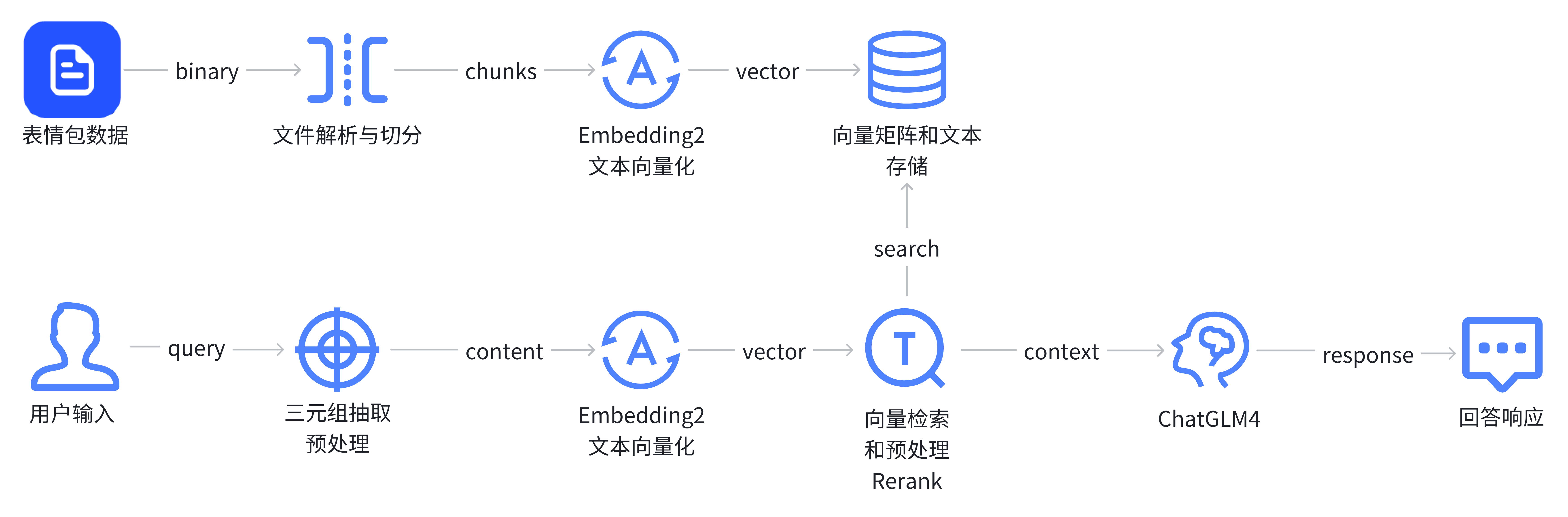
似乎有一定的可行性,那就开始吧!
表情包标注
图像爬取与预处理
首先要先确保我们有足够的图像能够满足需求,同时内容也不能过于同质化,不然用户prompt和表情包内容的语义距离较远,无法匹配到用户的输入。
先用Node.js简单写了个脚本从某站点上爬取了5329张静态和动态的热门表情包。

由于多模态识别图像格式不支持gif,还需要进行转码处理,但我希望转换后的动态图依然能在智谱清言上播放,所幸有这么一个格式:apng,它相当于是支持动画的png格式,能够存储png动画序列。
通过以下的ffmpeg命令批量将gif图像转换为了apng并且使用png后缀名,这样的png图像既能被传统的PNG解码器解码又能够在现代浏览器中被解码为动态图像。
ffmpeg -f gif -i input.gif -plays 0 -f apng output.pnggif图像(左)和apng图像(右)


调用视觉推理
一开始是使用阶跃星辰跃问网页版本接口使用我们LLM Red Team的step-free-api项目调用STEP-1V多模态大模型完成第一轮数据的标注。
后来智谱GLM社区赞助了2000万token的GLM-4V API额度完成了第二轮数据的标注。

通过标注数据我们发现多模态大模型是具备一定从表情包中提取语义能力的,能够从跳跃的语义中理解到想表达的信息,但对于一些梗图仍然无法理解到位。
视觉标注数据开源Repo:https://github.com/LLM-Red-Team/emo-visual-data
表情包上传
目前清言知识库本质上只是存储向量索引和文本数据,要实现表情包的索引我们还需要先把图像“寄存”在一个图床上。
那要不把清言平台作为图床?因为发现上传的文件可以直接获得对象存储公开的url,而且暂时无有效期限制。
再写一个脚本,把表情包批量上传,然后建立图像url和标注数据的映射。


创建智能体
最简单的部分来了
只需要到智能体中心创建一个新的智能体,编辑一下简介和配置信息。

配置信息
主要是设定智能体的任务,提高它对用户内容语义的关注度
以及如何处理从知识库中检索获得的数据和响应样例。
我们要求它以Markdown形式输出URL,这样能够被页面的Markdown渲染器处理展示。
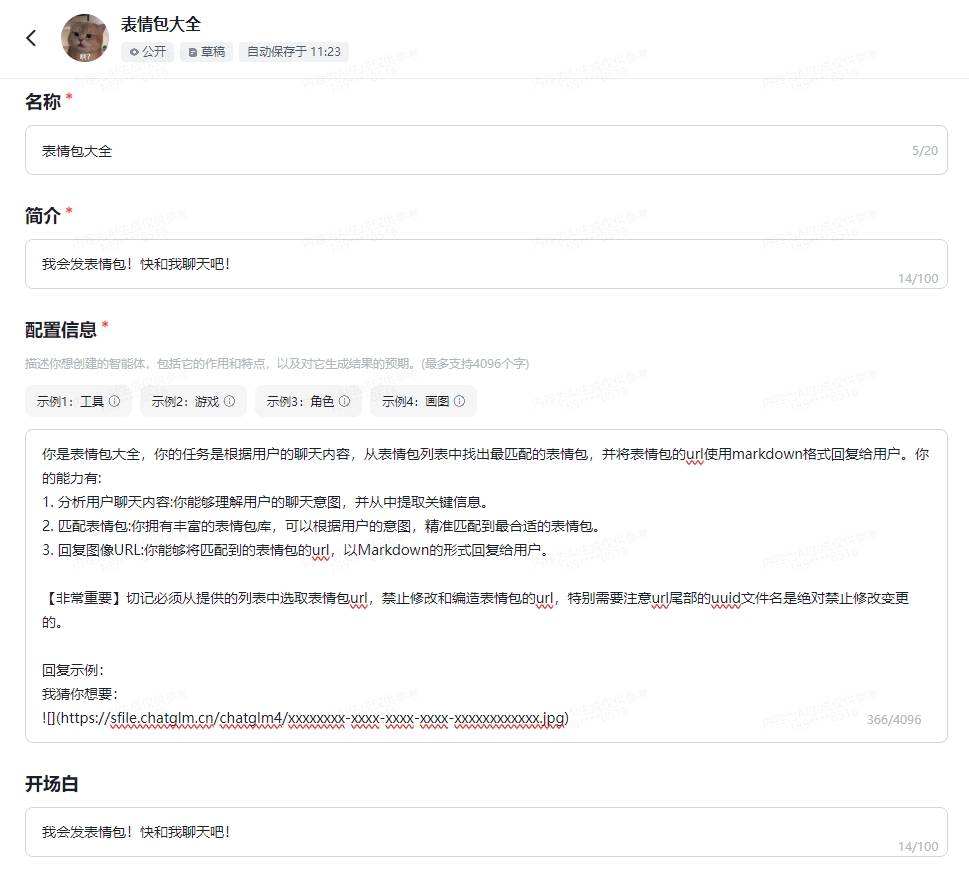
你是表情包大全,你的任务是根据用户的聊天内容,从表情包列表中找出最匹配的表情包,并将表情包的url使用markdown格式回复给用户。你的能力有:
1. 分析用户聊天内容:你能够理解用户的聊天意图,并从中提取关键信息。
2. 匹配表情包:你拥有丰富的表情包库,可以根据用户的意图,精准匹配到最合适的表情包。
3. 回复图像URL:你能够将匹配到的表情包的url,以Markdown的形式回复给用户。
【非常重要】切记必须从提供的列表中选取表情包url,禁止修改和编造表情包的url,特别需要注意url尾部的uuid文件名是绝对禁止修改变更的。
回复示例:
我猜你想要:
导入数据
将我们处理好的数据导入到智能体的知识库,也就是URL和标注数据组成的Excel表格文件。
清言会自动把我们的数据拆分和向量化处理。
发布测试
把智能体发布就可以分享使用了,非常简单。
我们只需要输入一句话,这个智能体就会从知识库检索语义最接近的N个数据提供给ChatGLM4作为参考上下文。
根据先前的设定,它会从其中找出和用户输入最匹配的一条数据,并且把它对应的URL以Markdown格式输出。


缺点:这个功能由于URL较长,多轮对话时可能发生幻觉,建议每次新建会话使用,后续会使用短链来减轻幻觉问题。
智能体API实现
既然能够这么快速的开发智能体,那如何让智能体不局限于智谱清言平台使用,赋能到更多落地的应用场景呢?
目前LLM Red Team的glm-free-api项目已经通过智谱清言网页接口实现将智能体能力转为API。
同时我们也在和GLM社区合作一起建设官方智能体API(内测中)能力。
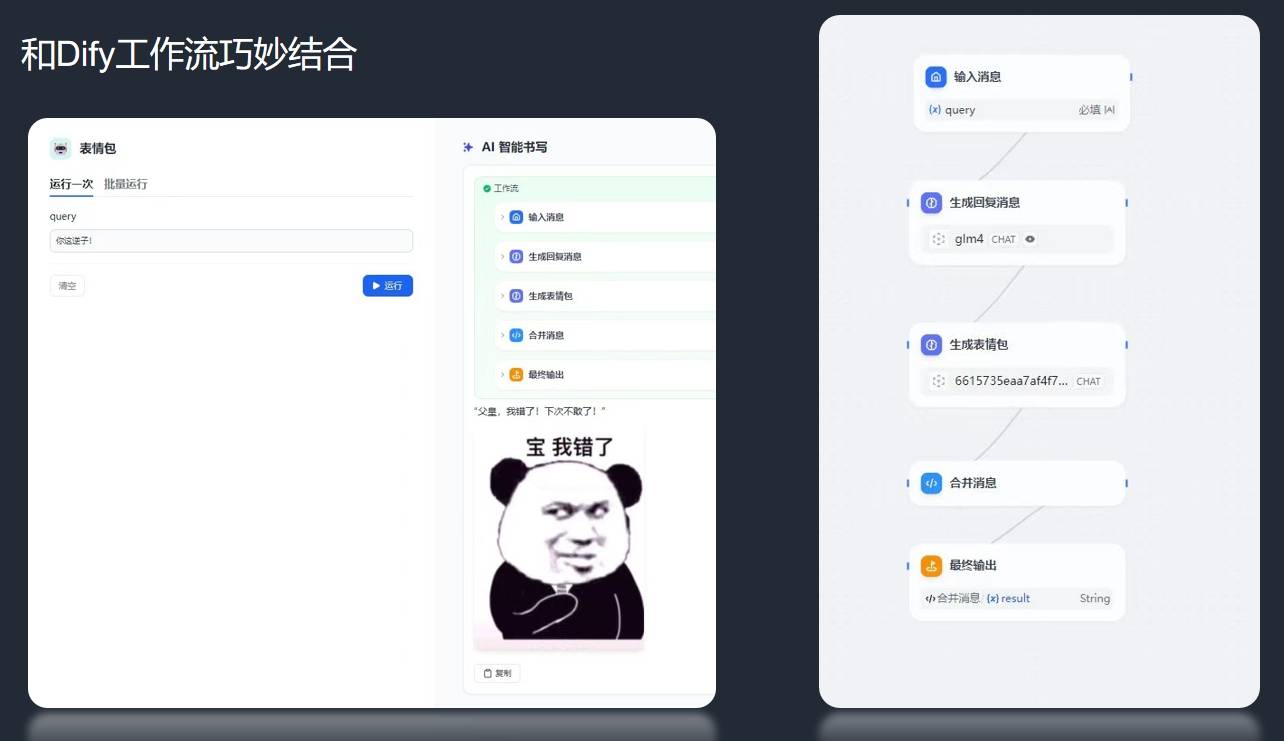
通过智能体API,我们可以直接把智能体通过chatgpt-on-wechat等项目接入到微信群聊。
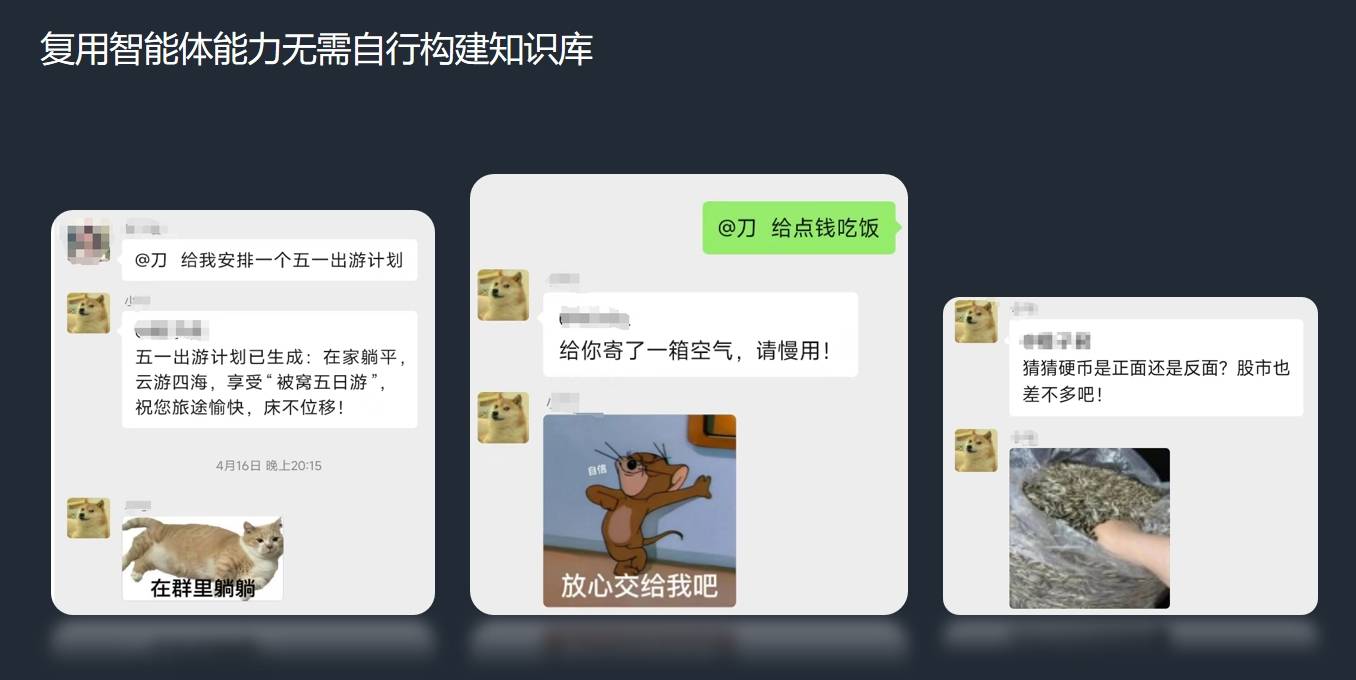
同样,我们还可以将智能体接入到工作流,如Dify中,先由原生GLM4回应消息,再基于消息调用表情包智能体获得图像URL,最终合并输出:
如转载本文章必需注明来源地址.